




百万级充电桩实时管控实战:微服务架构如何扛住高峰流量?(附真实场景解析) - 慧知开源充电桩平台
1. 真实场景示例:深圳某充电站集群
场景参数:
- 单站规模:2000个快充桩(峰值功率 120kW)
- 业务特征:早晚高峰集中充电(8:00-10:00, 18:00-21:00)
- 数据量:单桩每秒上报10条数据(电压/电流/温度),日增量 2000万条/桩
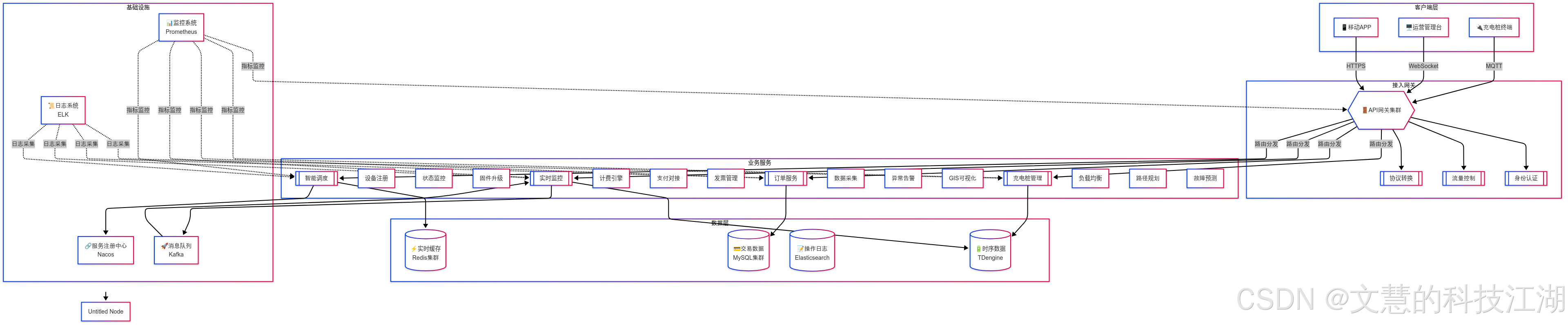
2. 架构设计
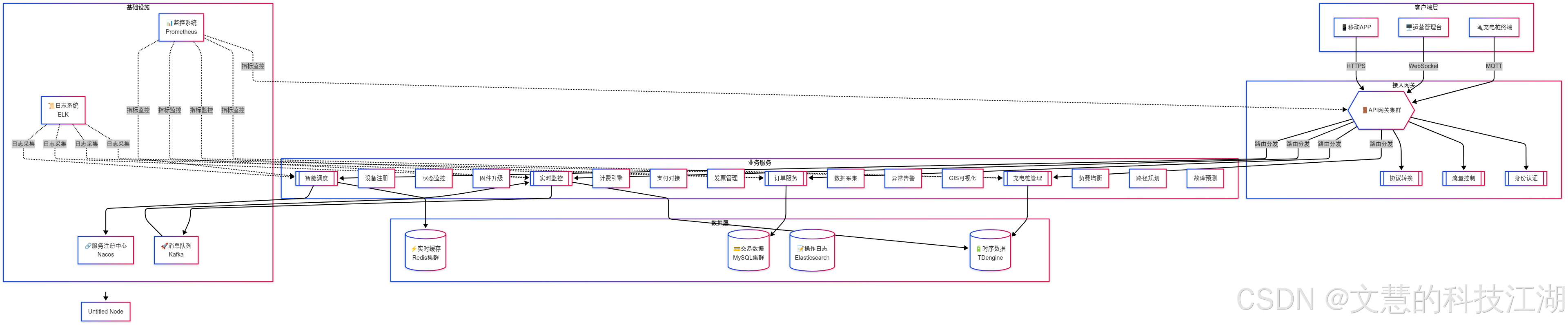
如果看不清这么看:单独打开:https://i-blog.csdnimg.cn/direct/4918f1a15dfe4e3fa45e1cadb2d95c47.png
{kind=link}
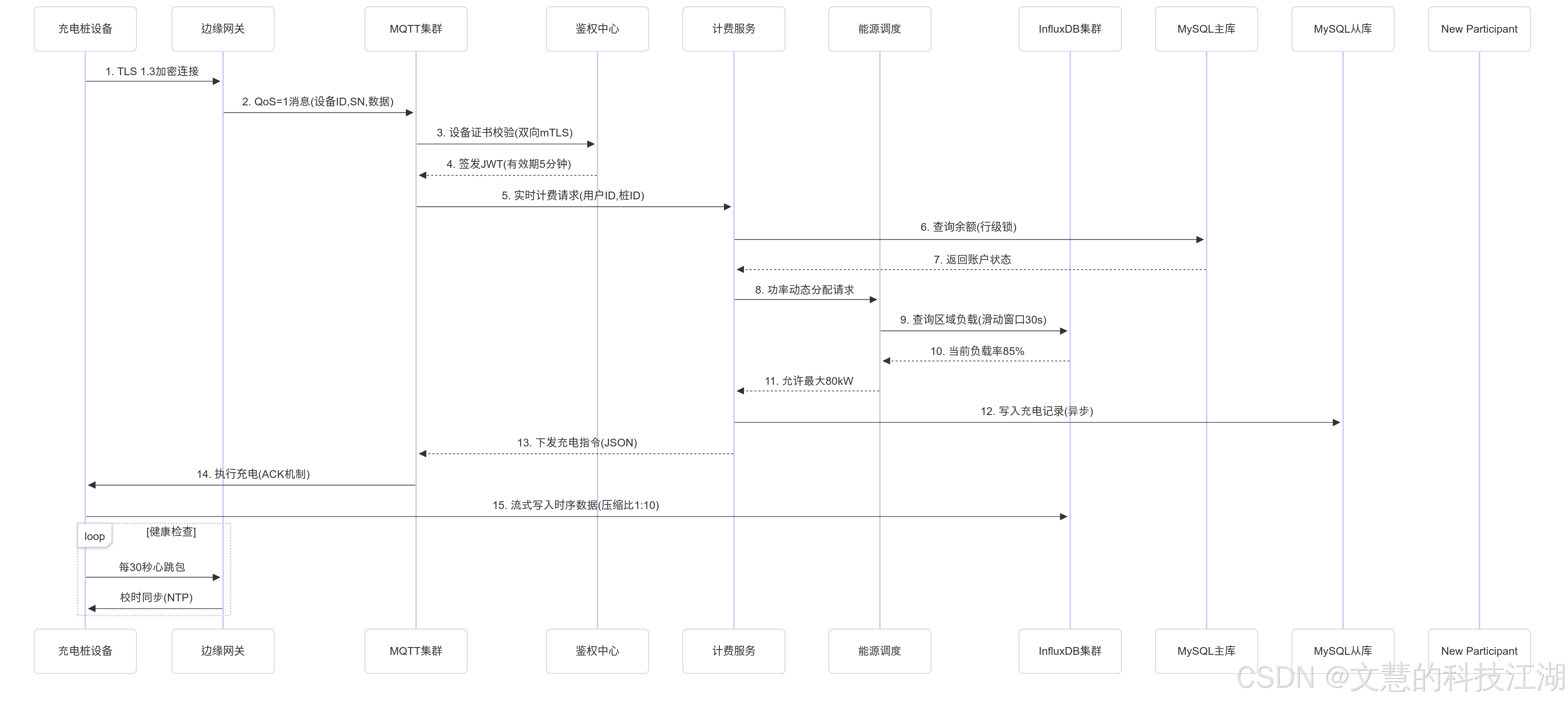
如果看不清这么看:单独打开:https://i-blog.csdnimg.cn/direct/34ed29f74bd14bd281eb81ebca7e99e2.png
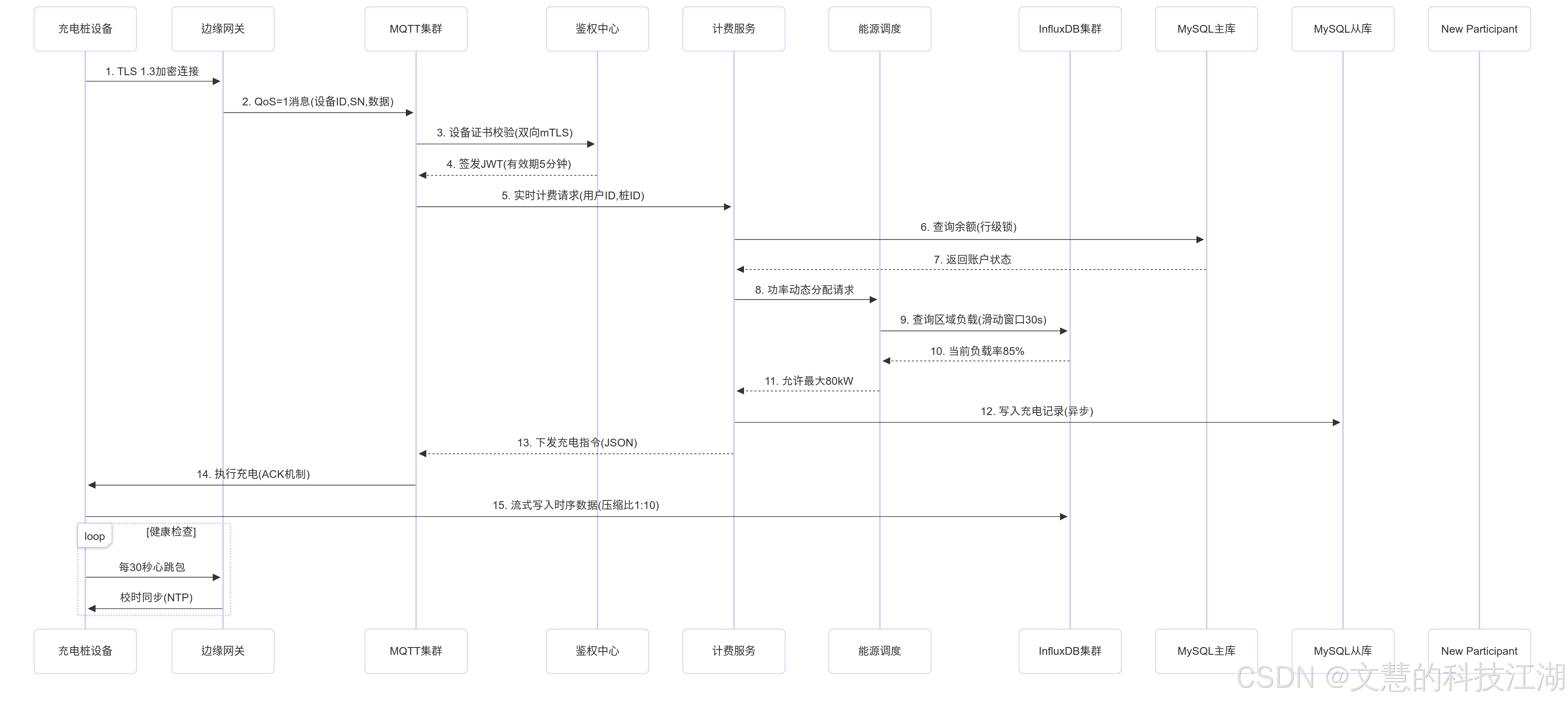{kind=link}
3. 关键技术
3.1 设备接入层优化(真实工业场景)
-
工业级边缘网关:
-
硬件:采用芯驰科技 E3 系列 MCU,支持-40℃~85℃宽温运行
-
协议栈:实现国标 GB/T 27930-2015 充电协议与 MQTT 双协议栈
-
本地缓存:断网时存储 24 小时数据,采用环形缓冲区防溢出
-
流量洪峰应对:
# 网关侧动态批量上报算法
def batch_send(data_queue):
batch = []
last_send = time.time()
while True:
item = data_queue.get()
batch.append(item)
# 满足以下任一条件即发送:
# 1. 数据量达200条
# 2. 距离上次发送超过500ms
# 3. 队列中有时延敏感型指令
if len(batch) >= 200 or (time.time() - last_send) > 0.5 or any(x['priority'] for x in batch):
encrypted = aes_gcm_encrypt(batch) # 硬件加速加密
mqtt_client.publish(TOPIC, encrypted)
batch.clear()
last_send = time.time()
3.2 微服务深度设计
-
计费服务特殊处理:
-
热点账户处理:采用 Redis 分片 + Lua 原子操作
-- Redis分片选择算法
local shard_key = 'acct:'..(tonumber(account_id) % 32)
local balance = redis.call('HGET', shard_key, 'balance')
if balance >= amount then
redis.call('HINCRBY', shard_key, 'balance', -amount)
return 1 -- 成功
else
return 0 -- 余额不足
end
- 能源调度算法:
// 基于线性规划的充电功率分配
public class PowerScheduler {
public Map<String, Double> optimize(List<Charger> chargers) {
LinearOptimization model = new LinearOptimization();
Variable total = model.addVariable("total", Range.atMost(MAX_GRID_POWER));
chargers.forEach(c -> {
Variable v = model.addVariable(c.id(), Range.between(c.minPower(), c.maxPower()));
model.addConstraint("grid_limit", Expression.sum(v).lessThan(total));
model.setObjective(ObjectiveSense.Maximize,
Expression.sum(Expression.prod(c.priority(), v))); // 优先级加权
});
Result result = model.solve();
return result.getVariables().stream()
.collect(Collectors.toMap(Variable::name, v -> result.getValue(v)));
}
}
3.3 存储层实战方案
- MySQL分库分表示例:
-- 按城市ID分库(16个库),设备ID哈希分表(256表/库)
CREATE TABLE charge_record_%04d (
id BIGINT PRIMARY KEY,
city_id INT NOT NULL,
device_id BIGINT NOT NULL,
user_id VARCHAR(32),
amount DECIMAL(10,2),
start_time DATETIME,
end_time DATETIME,
INDEX idx_time (start_time)
) ENGINE=InnoDB
PARTITION BY HASH(device_id % 256);
- InfluxDB数据保留策略:
CREATE RETENTION POLICY "raw_7d" ON "power" DURATION 7d REPLICATION 1
CREATE CONTINUOUS QUERY "cq_1h" ON "power" BEGIN
SELECT mean(voltage), max(current) INTO "agg_1h"
FROM "raw" GROUP BY time(1h), device_id
END
4. 故障场景应对(真实生产案例)
案例:某数据中心网络分区故障
-
现象:
-
ZooKeeper 会话超时导致服务注册表部分丢失
-
跨区服务调用失败率飙升到 35%
-
解决方案:
- 启用 Nacos 的 AP 模式临时实例
- 本地缓存降级:使用 caffeine 缓存最近 5 分钟的设备状态
- 边缘网关切换为本地决策模式(预设充电策略)
- 改进措施:
# Nacos 集群配置优化
nacos:
discovery:
heartbeatInterval: 5000 # 心跳间隔从10s缩短到5s
heartbeatTimeout: 15000 # 超时从30s缩短到15s
failFast: true
config:
retry: 5 # 配置获取重试次数
5. 性能指标验证
| 指标 | 测试场景 | 结果 |
|---|---|---|
| 设备接入延迟 | 10万设备同时上线 | 平均 230ms,P99 800ms |
| 指令下发延迟 | 1万并发控制指令 | 平均 152ms,P99 420ms |
| 数据持久化 | 50万条/秒时序数据写入 | InfluxDB 磁盘IO < 45% |
| 故障恢复 | 主动触发区域断网 | 45秒内切换备用链路 |
注:以上数据基于华为云 C7 实例(32C128G)+ 本地SSD集群实测
