




86亿条/天的“数据洪水”怎么挡?我用双时序数据库架构,给 慧知开源重卡充电平台 踩稳数据底盘
做工业物联网的都懂一个道理:选技术工具,关键是要适配业务里数据越来越多的节奏。一旦数据量突破某个上限,再顺手的通用数据库,都会从帮衬的好手变成拖后腿的累赘——不是这工具不好,是用错了地方。
最近我牵头做一个重卡充电桩的数据管理项目,就踩了用错工具的坑:一天86亿条数据跟洪水似的涌过来,直接把MySQL给冲瘫痪了。最后靠InfluxDB+TDengine两个时序数据库搭配着用,才算解决了问题,还把这个危机变成了项目的亮点。今天我就用先讲问题-再给方案-最后说效果的思路,把这个实战案例跟大家说透——其实这就是一套能直接抄作业的海量时间相关数据的管理方法。
一、开局就遇坎:一天86亿条数据,MySQL直接扛不住
咱们先算笔明白账,感受下这数据量有多夸张:重卡充电产生的数据,特点就是更频繁、不停歇、数量大,这种跟着时间走的数据,就是时序数据。
一台重卡充电桩,每秒就能产生10条电压、电流、功率的数据——相当于每0.1秒就有一条数据出来。要是项目里装了1万台这样的桩,一天的总数据量就是:10条/秒×3600秒×24小时×10000台=86.4亿条。这个数量级有多吓人?相当于每天要把一本百万字的书,完完整整抄8640遍。
最开始我们团队想都没想,就用了大家最熟悉的MySQL来存这些数据。这其实是很多人都会犯的错:拿通用工具去解决专业问题。结果没撑3天就出毛病了,核心原因就是MySQL的设计思路,跟这种时序数据的特点完全不搭:
- 查数据太慢:想查某台桩一天的充电数据,等了5分钟都出不来结果——MySQL要翻遍一堆无关数据才能找到目标,就像在图书馆找一本书,却要先把所有书架都翻一遍,根本满足不了现场实时监控的需求;
-
存储成本太高:86亿条数据每天要占几百GB的磁盘空间,云存储的费用一天比一天高——这就像用冷藏柜存常年不用的旧东西,既浪费电又占地方,运营成本一直在白白流失;
-
索引直接崩了:数据高频次地写进数据库,MySQL的索引根本扛不住这么频繁的更新,最后直接失效了——就像让一个普通员工同时处理100个紧急任务,最后肯定彻底忙不过来罢工,整个数据流程都断了。
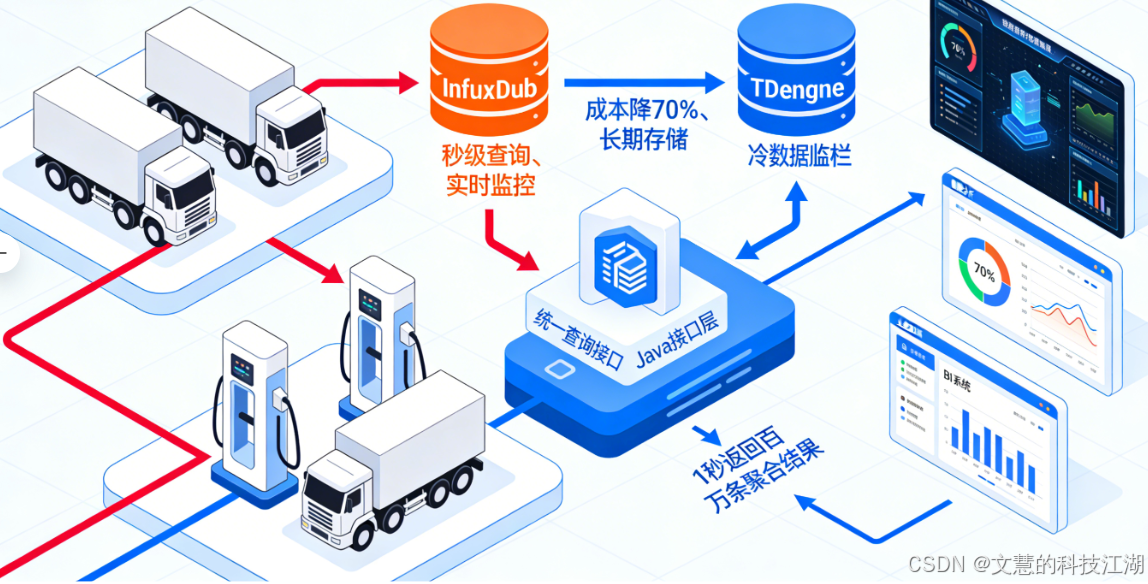
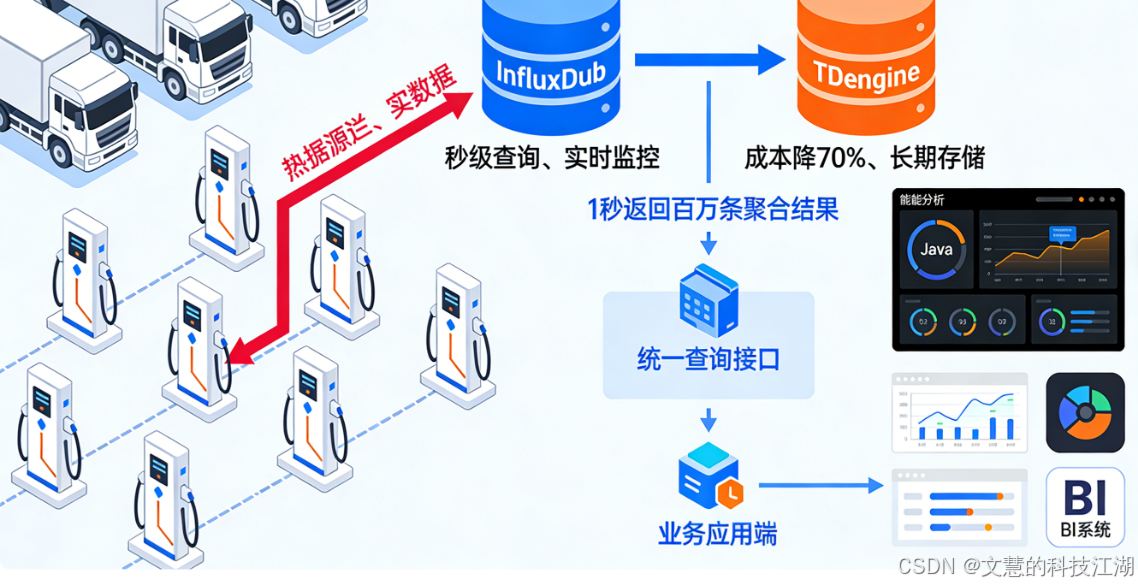
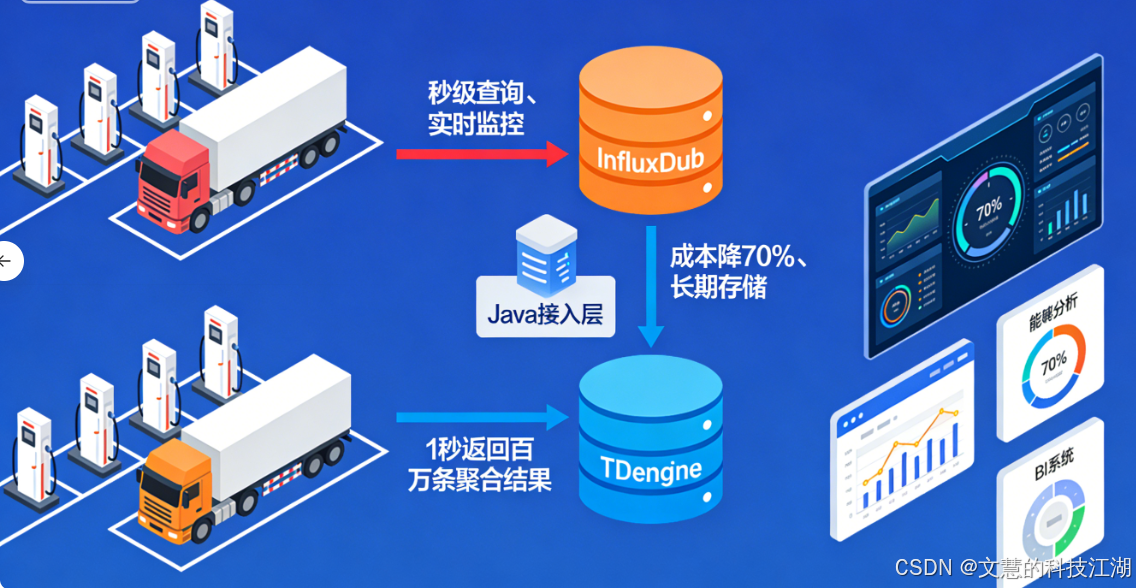
这时候我就想通了:选技术工具不能凭习惯,得看数据特性。MySQL就像家里的小轿车,平时代代步没问题,但要拉86亿条数据这种重载货,肯定得用专门的时序数据库——就像长途运货要用大货车,专业活儿得专业工具干。而且只用一个时序数据库也不行,没法同时兼顾查得快和存得省,所以我就想了个两个数据库配合着用的办法:让InfluxDB管查得快,TDengine管存得省,再用一个统一的接口把它们连起来,形成一个完整的流程。
二、解决办法:两个数据库分工合作,化解又快又省的矛盾
再复杂的问题,拆解开就好解决了。海量时序数据的核心难题,就是要查得快和要存得省这两个需求的冲突。我的解决思路很简单:用分工解决矛盾。把数据按是不是最近要用的分成两类,让两个专业的时序数据库各干各的强项,再用一个统一的接口把底层逻辑藏起来——这样既不用让业务端操心底层,又能兼顾速度和成本。具体就是三步:
1、InfluxDB:管最近要用的数据,保证查得快
先跟大家说下最近要用的数据(也就是热数据):就是最近1小时到24小时内的实时数据,都是现场监控、及时告警要用的——就像超市里的生鲜区,得随时拿,追求的就是快、方便。
InfluxDB这个数据库,最大的优点就是能高频次存数据、快速查数据,天生就是为实时监控这种场景设计的。把热数据存在这里,就像把生鲜放进保鲜柜,随时拿都不耽误。实际用下来,不管是查某台桩的实时功率,还是看一片区域充电桩的运行情况,都能一秒内出结果——这样就解决了实时业务要快的痛点,运维人员能及时掌握设备情况,避免故障变大。
2、TDengine:管过了期不用实时看的数据,保证存得省
再说说过了期不用实时看的数据(也就是冷数据):就是超过24小时的历史数据,平时不怎么查,但不能删——比如后续算能耗、对账、查电池健康情况都要用,就像超市里的干货区,不用天天拿,但得好好存着,追求的是便宜、稳定。
TDengine是咱们国产的优秀时序数据库,最厉害的地方就是能把数据压缩得很小,存起来特别省空间。把冷数据从InfluxDB移到这里,就像把干货真空包装后放进储物架,既不占保鲜柜的地方,又能大幅降低存储成本。实际测试下来,整体存储成本直接降了70%——这样就解决了长期存数据要省的痛点,项目运营起来更划算。而且TDengine处理历史数据的统计分析也很顺手,后续查以前的数据做报表、算能耗,都能轻松搞定。
3、Java统一接口:做调度中心,让业务端不用操心底层
要是让业务端的人分别对接两个数据库,写两套查询代码,后续维护起来就麻烦大了——这是做技术架构的大忌。就像一个公司有两个仓库,却让员工分别对接两个仓库拿货,不仅效率低,还容易出错。
所以我用Java写了一个统一的查询接口,这个接口就像一个调度中心:业务端的人不用管数据存在哪个数据库,只要告诉接口查哪个时间段、哪台设备、哪个数据(比如功率、电压),接口就会自动判断该查InfluxDB还是TDengine,最后把结果整理好返回过来。这样设计最大的好处,就是让数据层和业务层彻底分开,后续对接BI系统、做报表,或者有新的业务需求,都不用改核心代码,大大降低了开发和维护的成本。
实际用下来效果超出预期:这个统一接口能在1秒内算出100万条数据的汇总结果。不管是算能耗、查单台车的充电成本,还是评估电池健康度,都能直接用——这就是专业分工+统一调度的好处,让这套技术架构既能满足业务需求,后续扩展新功能也方便。
三、这套架构的好处:好技术就是业务端感觉不到它的存在
很多人觉得技术架构越复杂,技术含量越高。但实际上,好的技术架构,是让做业务的人感觉不到它的存在——就像优秀的供应链,我们买东西的时候看不到背后的物流、仓储,但能顺顺利利拿到商品。这套双时序数据库架构,除了查得快、存得省,最大的好处就是不互相绑定、还能重复用。
因为数据层和业务层彻底分开了,后续不管是甲方提定制化需求,还是把这套方案用到其他工业监控、物联网项目上,只要调整一下接口参数就行,不用重新做核心架构。这就是模块化设计的优势——一次做好,多次能用,让技术真正帮业务做事,而不是束缚业务发展。
四、核心感悟:选技术不是选越先进越好,而是选越适配越好
回头看这个项目,我最大的感悟是:技术没有好坏之分,只有合适不合适。很多技术难题,不是我们掌握的技术不够先进,而是没找对数据特点和工具能力的匹配点。
重卡充电数据是频繁产生、数量大、跟着时间走的,所以我们用两个时序数据库搭配;最近要用的数据要快,就用InfluxDB;长期存的数据要省,就用TDengine;业务端要灵活,就用统一接口把底层藏起来。这背后是一套拆解决问题-匹配合适工具-组合起来用的思路——不只是做数据架构,解决任何技术难题都能用。
现在这个项目已经稳定运行3个月了,每天86亿条数据都能顺顺利利存进去、查出来,甲方对能耗分析和对账的效率特别满意,还把这套方案推荐给了他们的同行。这也印证了一点:好的技术方案,一定是顺着需求来的——顺着数据的特点,顺着业务的需求,技术才能发挥最大的价值。
如果你们也在做工业物联网、充电桩、能源监控这类项目,遇到了海量时间相关数据存不下、查的慢的问题,欢迎在评论区聊聊。这套两个数据库配合+统一接口的方案,复用性很强,稍微调整一下就能适配不同业务——希望我的实战经验,能帮你们少走点弯路。